
A research team led by Professor Zhao Yue from the School of Astronautics at Harbin Institute of Technology (HIT) has made important progress in the research of CLIP fine-grained alignment technology.
The research findings, titled MSG-CLIP: Enhancing CLIP's ability to learn fine-grained structural associations through multi-modal scene graph alignment, have been published in Pattern Recognition, an international academic journal in the field of pattern recognition and artificial intelligence.
This achievement provides key technical support for improving the precise image-text understanding capability of cross-modal artificial intelligence models.
As a core representative of cross-modal pre-trained models, CLIP has become a critical foundational technology in core AI fields such as image-text retrieval, visual question answering, and image-text generation, thanks to its powerful image-text semantic alignment capability.
However, as the core module for CLIP to comprehend image-text semantics, fine-grained alignment has long suffered from pain points including low alignment accuracy and insufficient structural learning ability, which has become a key bottleneck restricting the application of CLIP in high-end visual understanding scenarios.
Unlike traditional CLIP models that can only achieve coarse-grained semantic matching, breakthroughs in fine-grained alignment technology are the core prerequisite for AI to accurately interpret the deep semantics of images and texts.
Targeting the technical pain points, Professor Zhao's team conducted systematic research and proposed the MSG-CLIP framework.
Through a multi-modal scene graph alignment mechanism, the framework realizes dual fine-grained precise matching: entity-level modal alignment and triple-level relational alignment, which solves the core defects of traditional CLIP in fine-grained alignment, such as lack of structural information and large matching errors.
Experimental results show that without increasing model parameters, MSG-CLIP achieves a substantial 11.2 percent performance improvement over the baseline model on the authoritative benchmark dataset VG-Attribution, and a notable 2.5 percent performance gain on another authoritative benchmark dataset VG-Relation.
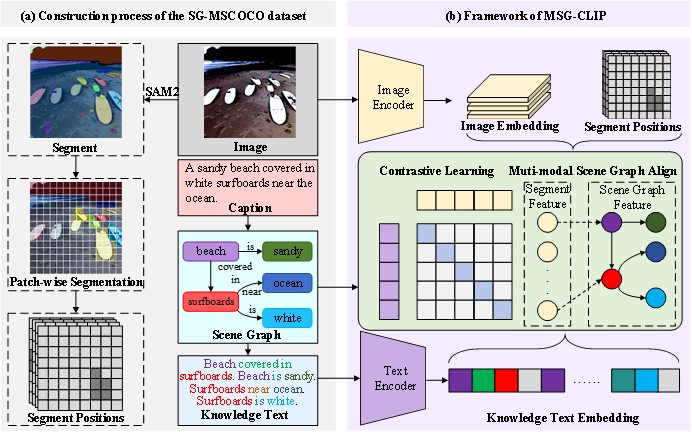
A schematic diagram showing the overall MSG-CLIP framework. [Photo/hit.edu.cn]
HIT is the first affiliated party of this paper. Lyu Xiaotian, a doctoral candidate at the School of Astronautics, is the first author, and Professor Zhao is the corresponding author.
This research was supported by the National Natural Science Foundation of China, the Key Research and Development Program of Artificial Intelligence in Heilongjiang province, and other projects.
Paper link: https://www.sciencedirect.com/science/article/abs/pii/S0031320325014578?via%3Dihub=